
Foundational Concepts
9 Matrix Algebra to Solve a Linear Regression
Learning Objectives
To illustrate how matrix algebra can solve a linear regression.
To continue using R.
Resources
Gotelli & Ellison (2004, appendix)
Introduction
Matrix algebra is helpful for quickly and efficiently solving systems of linear equations. We will illustrate this by using it to solve a linear regression.
Matrix Formulations of Regression
The matrix algebra formulation of a linear regression works with any number of explanatory variables and thus is incredibly flexible.
Recall that the model for a simple linear regression is y = mx + b, where b and m are coefficients for the intercept and slope, respectively. Let’s rearrange this slightly and rewrite m as b1:
y = 1b0 + xb1
Note that b0 is equivalent to 1b0. In other words, the right-hand side of this equation consists to the sum of two products: 1 times the intercept plus the measured value of x times the slope. We can now summarize this in matrix form:
Y = Xb
where
- X is a matrix with as many rows as there are data values and two columns (a column of 1s and a column of x values)
- b is a vector of two coefficients (intercept and slope)
When we fit a simple linear regression to data, we are determining the coefficients associated with each variable. Equation A.14 from Gotelli & Ellison (2004) states that the coefficients (i.e., b) can be calculated as
b = [XTX]-1[XTY]
Chlorella Example
Let’s use a simple example to see how these calculations work. We will use a dataset containing the maximum per-capita growth rate of an alga, Chlorella vulgaris (y), and light intensity (x). These data are from Ellner & Guckenheimer (2011). The dataset is available in CSV format through the book’s GitHub site. Download it into the ‘data’ sub-folder within your SEFS 502 folder. Open the course R Project and then read the dataset into R:
chlorella <- read.csv("data/chlorella.csv", header = TRUE, row.names = 1)
head(chlorella)
x y
1 20 1.73
2 20 1.65
3 20 2.02
4 20 1.89
5 21 2.61
6 24 1.36The column y is the vector of responses. The column x is the vector of values for the explanatory variable, light intensity.
To organize the linear regression model in matrix form, we need to combine each value of chlorella$x with a ‘1’ that can be multiplied by the intercept b0. We’ll organize the ones in a column, combine the two columns of explanatory variables, and convert the resulting object to class matrix:
X <- matrix(Note that
data = c(rep(1,11), chlorella$x),
nrow = 11)
rep(1,11) simply repeats the number 1 eleven times.
Now we can solve equation A.14:
b <- solve(t(X) %*% X) %*% (t(X) %*% chlorella$y)I have simply restated the equation from above, using transposes and inversions as discussed in the ‘Matrix Algebra Basics‘ chapter.
The result of these calculations, the object b, is an object that contains the intercept and slope of the equation relating Chlorella growth rate to light intensity.
[,1]
[1,] 1.58095214
[2,] 0.01361776
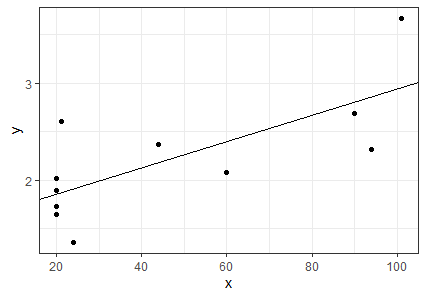
We can graph the Chlorella data and add to it the line described by this slope and intercept:
library(ggplot2)
ggplot(data = chlorella, aes(x = x, y = y)) +
geom_point() +
geom_abline(intercept = b[1], slope = b[2]) +
theme_bw()
Verification
We can verify our results by comparing them with the coefficients produced from the lm() (linear model) function:
lm(y ~ x, data = chlorella)
In this formula, the ~ means ‘as a function of’; here, we fit y as a function of x. The 1’s that are multiplied by the intercept are automatically accounted for when using lm() and related functions.
The coefficients are labelled here, and are identical to those that we calculated above.
Call:
lm(formula = y ~ x, data = chlorella)
Coefficients:
(Intercept) x
1.58095 0.01362 Extensions
Matrix algebra can also be used to calculate other types of information that can be extracted from a regression. Let’s walk through a few.
Predicted Values of y
The predicted value of y for each observation (row) is the value obtained by applying the coefficients obtained above to that observation’s value of x. In other words, this is the solution to the linear regression formula that we re-arranged above, Y = Xb:
Y_pred <- X %*% b
For verification, multiply a value of x times the slope, and add the intercept.
Residuals
The residual for each observation (row) is the difference between its actual and predicted values of y:
residuals <- chlorella$y - Y_pred
For verification, see resid(lm.res).
Predicted Values for a Range of x Values
The predicted values across a range of x values simply requires that we specify which values of x we want to use. Let’s use 50 values that span the range of x in our data:
X_range <- matrix(
data = c(rep(1,50), seq(from = min(chlorella$x), to = max(chlorella$x), length.out = 50)),
nrow = 50)
Y_range <- X_range %*% b
These could be the values that are graphed as a fit line in ggplot, for example (you can do so and compare to the above graph to verify).
Note that it isn’t necessary to use this many values when graphing a linear fit, but a large number of values would be helpful if we had transformed one of our variables and were back-transforming the fit for presentation – more values will show a smoother curve for the resulting non-linear fit.
Concluding Thoughts
The appeal of this matrix formulation of a linear regression is that it can be easily generalized to any number of explanatory variables – fitting a response as a function of two variables simply adds one column to X and one value to b, but does not change the matrix form of the equation, or the corresponding calculation. This gives the matrix formulation of this equation incredible flexibility.
References
Ellner, S.P., and J. Guckenheimer. 2011. An introduction to R for dynamic models in biology. http://www.cam.cornell.edu/~dmb/DynamicModelsLabsInR.pdf
Gotelli, N.J., and A.M. Ellison. 2004. A primer of ecological statistics. Sinauer Associates, Sunderland, MA.
Media Attributions
- chlorella
