
Blowing with the Wind
Wind power might seem to be too old of a technology when discussing energy sources of the future. After all, windmills date back to the era of the first major novel of Western literature, Don Quixote, written in 1605. Since Don Quixote’s futile attacks on windmills, technologies have changed, but the omnipresence of the breeze has not. Wind power makes use of an abundant resource to perform the same task that fossil fuel electricity generation does, with much greater efficiency. To paraphrase Bob Dylan, “the answer, my friend, is the blowing of the wind.”
Turbines
All electricity sources except photovoltaic solar panels use the same principle to create electricity: electromagnetic induction. Because of the connections between electricity and magnetism, moving a magnet through a coil of wire induces an electrical current in the wire. This principle of electromagnetic induction allows electricity to be created from the kinetic energy of motion, and is the basic physics that make generators work. A permanent magnet is not even necessary in a generator; the same effect can be achieved with the use of an electromagnet, in which a current is run around a piece of metal, causing it to be temporarily magnetized. Movement of wire relative to a magnet or electromagnet is all that’s needed to generate electricity.
It’s surprising to many, but these same kind of electric generators are the way that electricity is created from combustible material. In coal or fossil gas power plants, fossil fuels are burned and used to heat water, which evaporates into steam and pushes into turbines. All of that heat goes first to create kinetic energy. Large amounts of energy are lost in the process. Nuclear power also uses this method, so about two-thirds of all that energy from splitting atoms goes to waste as heat.
Heat → kinetic energy → electricityWind power or hydroelectricity:
Kinetic energy → electricity
Turning a turbine doesn’t require heat. Using the motion of wind or the flow of water to generate electricity is a much more direct route to electricity production. This is how wind power is generated, as well as hydroelectric power.

Delivering a wind turbine blade by Virginia Wright-Frierson.
History of wind power
The first documented usage of wind power was in a musical instrument, Hero of Alexandria’s wind-powered pipe organ. Windmills were used to grind grain in as early as the 7th century in present-day Iran and Afghanistan. These were spread to Europe in the 12th century, which led to their use in water pumping and land reclamation in the Netherlands in the 15th century.
The preferred nomenclature for devices that use wind to create electricity is wind turbine, not windmill since nothing is being milled. When arranged into an array, these are called wind farms. Wind farms are located both onshore and offshore, with the former creating the most power (0.22 TW generated onshore vs 0.02 TW offshore). Wind is generates the most electricity of any of the cleanest energy options. It’s over 7% of global electricity generation.
Public investment in wind power technology development was quite large in the United States during the Carter administration, spurring early innovation and making the US the early leader in renewable power generation. California in particular was the world center of wind electricity. In 1985, three wind farms, Altamont Pass (west of Livermore in the Bay Area), Tehachapi Pass (between Barstow and Bakersfield north of Los Angeles), and San Gorgonio (near Palm Springs east of LA), generated 89% of the world’s wind power. Altamont alone generated 50% of the world’s wind electricity, with 6700 turbines of various designs, 630 MW of capacity, and a 14% capacity factor.
Many of the turbines looked similar to those popular today: 3 blades arranged in a fan shape. There were also some 2-blade models, a design that has lost favor due to increased maintenance costs and noise. Some eggbeater-shaped vertical-axis wind turbines (VAWTs) were installed at Altamont as well. These designs have the advantage of not needing to rotate into the wind, due to their rotational symmetry, but ultimately cannot be built as high as a horizontal-axis wind turbine (HAWT). Most of the slick designs of today’s wind turbines are HAWT.
There were some early missteps that required the technology to evolve. The 1980s designs usually used turbines that would point downwind. A downwind orientation occurs naturally from the forces of the wind if the turbine is allowed to rotate about the tower. However, downwind-facing turbines end up being less efficient, for a few reasons. They creating less power due to the blocking of the flow that comes from the tower. There is also a steady beating sound as each blade whips past the tower. Downwind turbines are also subject to more stress and break down more easily. Now wind turbines are upwind-orientated, which requires a motor to be embedded in the turbine to continually face it into the wind, in a process called “yaw control.” Upwind-oriented turbines are more efficient, and cause less wear and tear on the equipment as well.
A devastating misstep for local raptor populations was the use of scaffolded towers. These were attractive to large birds like golden eagles or condors as perches, and ultimately caused many birds to perish in collisions with the blades. Altamont Pass is a migration zone, that has much more bird traffic than most wind farms. Most of the bird deaths worldwide from wind turbines have happened at Altamont Pass. Groups like the Audubon Society and the Center for Biological Diversity lobbied for years to have these particularly dangerous old turbines removed from Altamont. They were eventually removed and replaced with newer, more bird-safe models. The Audubon Society supports the expansion of wind electricity, provided that it is sited and operated in a way to avoid impacts on birds.
The main difference between 1980s wind turbines and those of today is the size. Modern wind turbines are marvels of modern engineering. A 5 MW turbine stands 150 meters in height from the ground to a vertically-oriented blade. It contains 900 tons of steel, over half in the tower, and the rest in the blades and foundation. The turbines at Altamont in 1985 were as small as 20 meters in height, and as large as 40 meters.
Offshore turbines are made even larger. They can have peak capacity of 15 MW each, and stand taller than the Space Needle, nearly 250 meters to the top of a blade. Most offshore turbines are typically anchored with foundations set into the seafloor in shallow waters. Some floating platforms that are tethered to the seafloor exist and could help expand offshore wind into locations like the west coast of the United States, where the continental shelf falls off quickly and not much shallow water exists.
Where is the wind?
To help understand where it’s windy, one might ask instead “why is it windy?” The power for circulations on Earth is ultimately driven by the Sun. Specifically, the equator is heated more than the poles and the circulation of the atmosphere and the ocean develops with the differential heating as the energy source. If the Earth didn’t rotate, air would rise in the tropics and sink at the pole. Although one rotation in 24 hours might not seem like much, it fundamentally shapes the motion of air and water. The equator is spinning at a speed of over 450 meters per second (about 1000 miles per hour), and as warm air moves poleward, it brings with it this angular momentum. Roaring winds result, which break apart into high and low pressure systems that characterize the day-to-day weather variability in midlatitudes. There is always wind in these regions, and gusts are especially strong in the winter. This means that in locations like Russia, Northern Europe or Canada, wind power is an excellent complement to solar power.
The above animation shows surface pressure anomalies for simulations of four imaginary Earth-like planets with different rotation rates. Each simulation starts at a constant temperature and an atmosphere at rest. Surface pressure is a good indication of the day-to-day weather systems that bring gusts of winds within the middle latitudes. Without rotation, the top left panel shows little variation in surface pressure. All the other simulations (half, equal and twice Earth’s rotation rate) show large variability developing, with smaller scale as rotation rate increases. By David Bonan and Eliza Dawson.
Winds get significantly stronger at higher elevation, as they are farther away from the frictional influence of the ground. The larger turbines of today are able to capture these stronger winds aloft more easily. Winds also tend to be stronger wherever the surface is slicker, most prominently over the ocean, but also over open plains, like in the midwest United States. Winds can also be particularly strong when they are forced through narrow canyons or through mountain passes.
The exception for winds worldwide is the area of the tropics known as the doldrums. This is the region with persistently weak winds, where sail ships use to float aimlessly for days until finally floating through the region. Equatorial regions don’t have much possibility for wind power generation, even offshore.
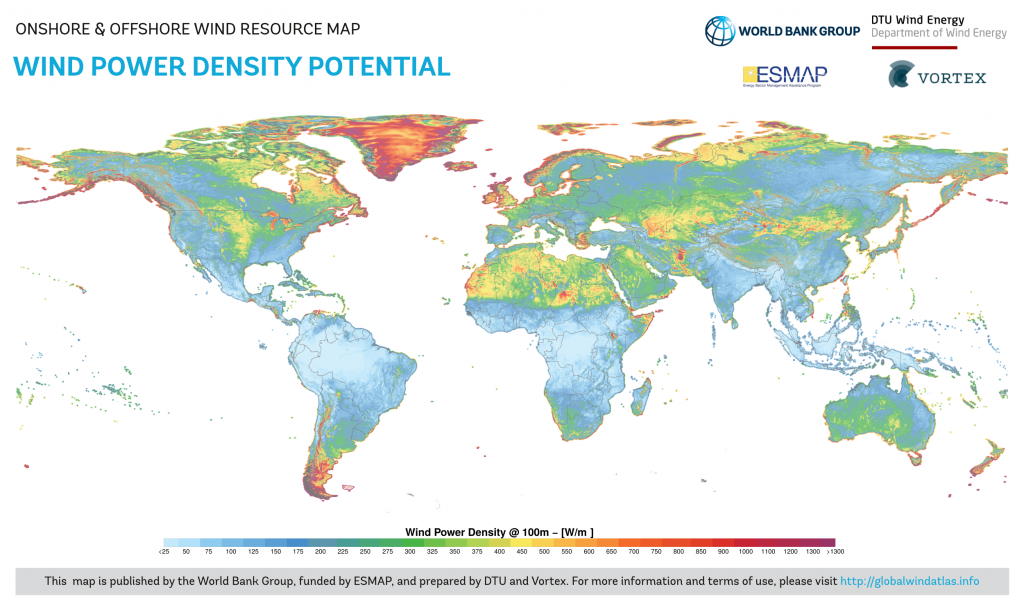
The above map shows the wind power that can be generated per swept area of the turbine.
Gusts to current
Wind turbines can only spin when the winds are sufficiently strong. There’s a cut-in speed for turbines where below the value, no power can be generated. Above this, more and more power up until a rated power, the nameplate capacity of the turbine. This amount of electricity is generated up until a cut-out wind speed, where the turbines are locked down to prevent damage.
So how much electricity can wind turbines generate compared with their nameplate capacity? Capacity factors for wind turbines have been increasing dramatically over recent years, and now average 40% for new installations. Offshore wind is even better, with 50% capacity factors for new installations. The price of wind installations currently is around $1.70 per watt, making it cheaper than fossil fuel power in almost all cases. Wind is blowing up!
How much to generate a tera?
At 40% capacity factor, we need 2.5 TW of nameplate capacity to generate 1 TW on average. This could be accomplished with 500,000 5 MW turbines as described above. Building this many turbines would require a huge amount of resources. The steel needed equates to 25% of current annual production, and about one fifth of the annual electricity production is needed, if these were to be constructed using all renewable energy. Of course, one wouldn’t expect to be able to roll out a new tera of generation within only a year. Five years is potentially a more appropriate timeline, which means that only 5% of steel production and 4% of electricity generation would be needed.
The land footprint to create a tera amounts to 125,000 km2, which is about five times the required space for solar power but still only two thirds of the size of Washington state. This assumes 20 MW/km2 as an average spacing, which is somewhat dense. There is plenty of land worldwide for a large amount of wind turbines. The total amount of wind power that could be generated over land is estimated to be around 70 TW.
Connect
UPROSE is “an intergenerational, multi-racial, nationally-recognized, women of color led, grassroots organization that promotes sustainability and resiliency through community organizing, education, leadership development and cultural/artistic expression in Brooklyn, NY.”
- Read about the community-led effort to bring offshore wind power that is manufactured locally to Sunset Park Brooklyn. This is hopefully the beginning of a huge climate justice victory for UPROSE and other community organizations.
- Follow UPROSE and executive director Elizabeth Yeampierre on social media, and read her interview with The Phoenix entitled “Five Ways to Build a Joyous Neighborhood Community.”
